大型語言模型與假新聞防治
資訊爆炸時代,我們每天都被大量的文字和符號淹沒。如果能有一位小助手幫我們處理這些文字訊息,那就太好了!讓機器具備語言能力,一直是資訊科學家積極探索的領域。近年來,大型語言模型如雨後春筍般出現,例如 GPT-4、Claude 3 或 Llama 3 等,它們已成為生成式人工智慧的重要角色。但是,大型語言模型究竟多「大」?它們如何生成通順的人類語言?為什麼它們的基礎都是 Transformer 架構?更重要的是,LLM 如何解決現實世界的難題,比如對抗假新聞的傳播?中央研究院「研之有物」專訪院內資訊科學研究所的古倫維研究員,為我們揭開 LLM 的神秘面紗,帶你深入淺出了解這場「語言革命」。
2022 年 11 月,OpenAI 發表了聊天機器人 ChatGPT,正式和地球人說 Hi。過去從來沒有機器可以使用如此自然流暢的文字語言和人類對話,這讓全世界的人工智慧研究都沸騰起來,2023 年迎來了生成式 AI 的狂歡派對。
大型語言模型(Large Language Model, LLM)就是這場派對最耀眼的明星,大家所熟知的 GPT-4、Claude 3,還有 Gemini 1.5 Pro 等,都是非常強大的 LLM。開放源碼的 LLM 則在 2023 年下半年開始大展身手,Meta 開發的 Llama 2/Llama 3 逐漸成為開源模型的主流,例如臺灣國家科學及技術委員會主導的繁體中文 LLM「TAIDE」,就是以 Llama 3 為基礎打造。
但是,你是否好奇大型語言模型背後的基礎架構是什麼?又為什麼叫做「大型」呢?《研之有物》訪談中研院資訊所古倫維,請她一一為我們解開謎底。
什麼是大型語言模型?
關於語言模型,古倫維說:「語言模型是一個很廣義的術語,模型就是用數學方式去模擬某些行為,前面加上語言,就是用數學方式去模擬人類語言的行為,例如『猜對下一個字』。」
如果語言模型前面再加上「大型」兩個字呢?古倫維接著說:「那就表示模型的參數量很大。早期 GPT-2 還可以勉強在自己的機器上跑,但是到了 GPT-3,基本上已經沒辦法這樣做了,大到我們無法望其項背的程度(笑)。」
具體來說,GPT-2 的參數量是 150 億(1.5 B),而發展到 GPT-3 時,參數量已經多達 1750 億(175 B)。古倫維比喻:「參數量很大的意思,就是語言模型用來解決問題的小秘訣很多。」例如,同樣是生成文字的任務,參數量越多(解題小秘訣越多)的模型,越容易猜對下一個字,同時效能也更好。
在大參數量的背景脈絡下,研究人員開始習慣將 GPT-3 之後的語言模型,包含各種延伸或精煉的小模型,都統稱為大型語言模型(LLM)。
大型語言模型就等同於人工智慧嗎?當然不是。
根據 IBM 的解釋,人工智慧是為了讓電腦和機器能夠模擬人類智慧,以及具備人類解決問題的能力。古倫維強調:「AI 這個名詞是更大的概念,而且 AI 通常還包含硬體,例如讓機器人像人一樣走路或是由電動車規劃最佳路線等。」
簡單來說,大型語言模型只是展現人工智慧的某種形式,它只是語言認知能力的展現,離通用人工智慧還很遠。「像人一樣,有心智活動和身體活動,LLM 比較屬於心智活動這塊」,古倫維說。
從詞符到向量:語言模型如何捕捉詞彙的語境關係?
讓我們再複習一下,語言模型是什麼?就是用數學方式去模擬人類語言的行為。例如給機器一段前言,讓機器去猜下一個字;猜對下一個字之後,再用前面的字當作前言,不斷猜下去,生成有意義、有結構的文本。
語言模型處理文字的規則和人類認知很不同,文字在語言模型中通常會轉換成詞符(Token)的一長串序列,Token 是語言模型處理的最小單位,可以是一個單詞、一個字母或對人類來說無意義的字串。
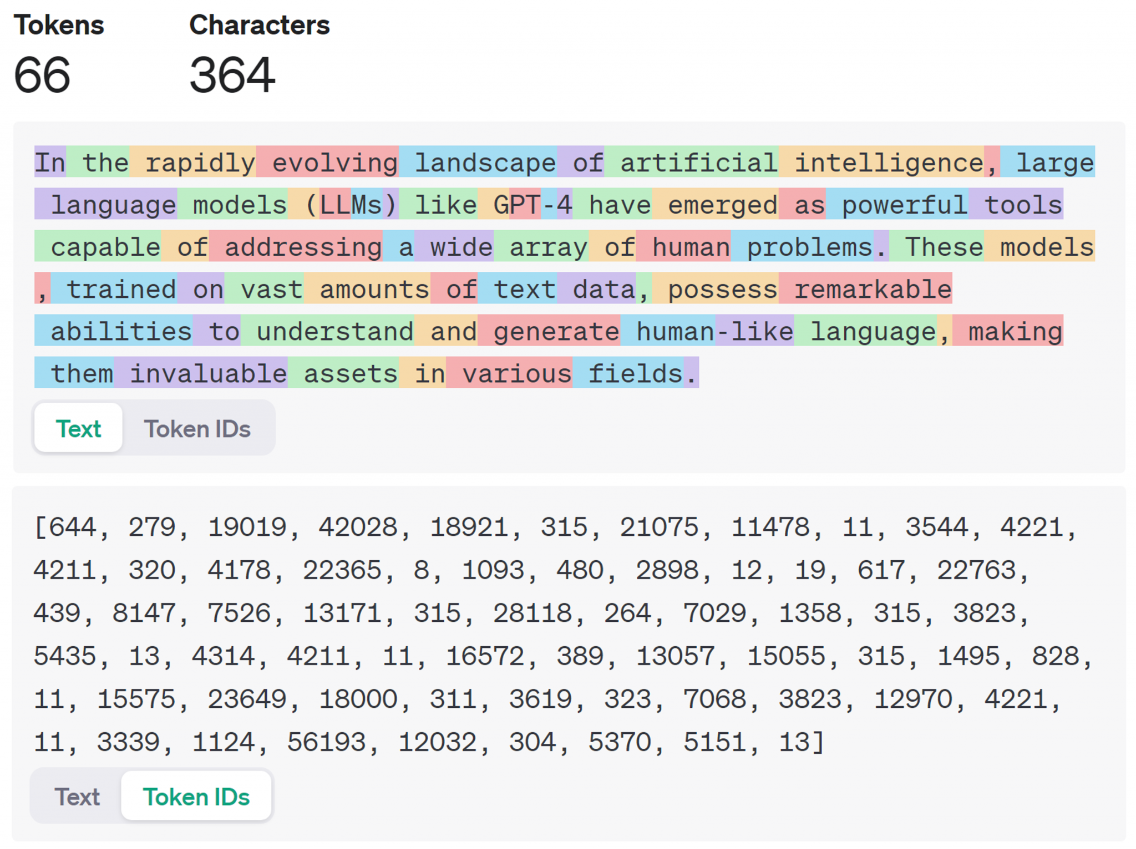
早期模型的 Token 拆分規則比較粗糙,彼此之間沒什麼關係。現在累積文本資料多了,加上深度學習技術,拆 Token 的方法愈來愈聰明,方便讓機器捕捉詞彙之間的語境關係。
要如何捕捉詞彙之間的關係?這就需要詞嵌入(Word Embedding)的技術。古倫維說:「詞嵌入基本上就是兩個概念。例如看到一群人在外行動,根據對這群人的理解,猜想某某人說不定也在裡面。這就是用附近的語境去定義這個字本身。另一方面,字也可以定義它附近的語境,例如猜想某某人的朋友應該都傾向學習新知等等。」
要精準捕捉詞彙關係,詞嵌入需要非常多的資料來訓練。首先,就是把文字拆成 Token,再把 Token 轉換成向量(Vector),幫助模型更好地理解 Token 和語境。
例如下圖,當我們輸入 food,語言模型可能會將 food 這個 Token 定義成:很常和 product 或 meat 一起出現的東西。而 food、product、meat 這三個 Token,都會表示成數值化的向量,這就是詞嵌入。
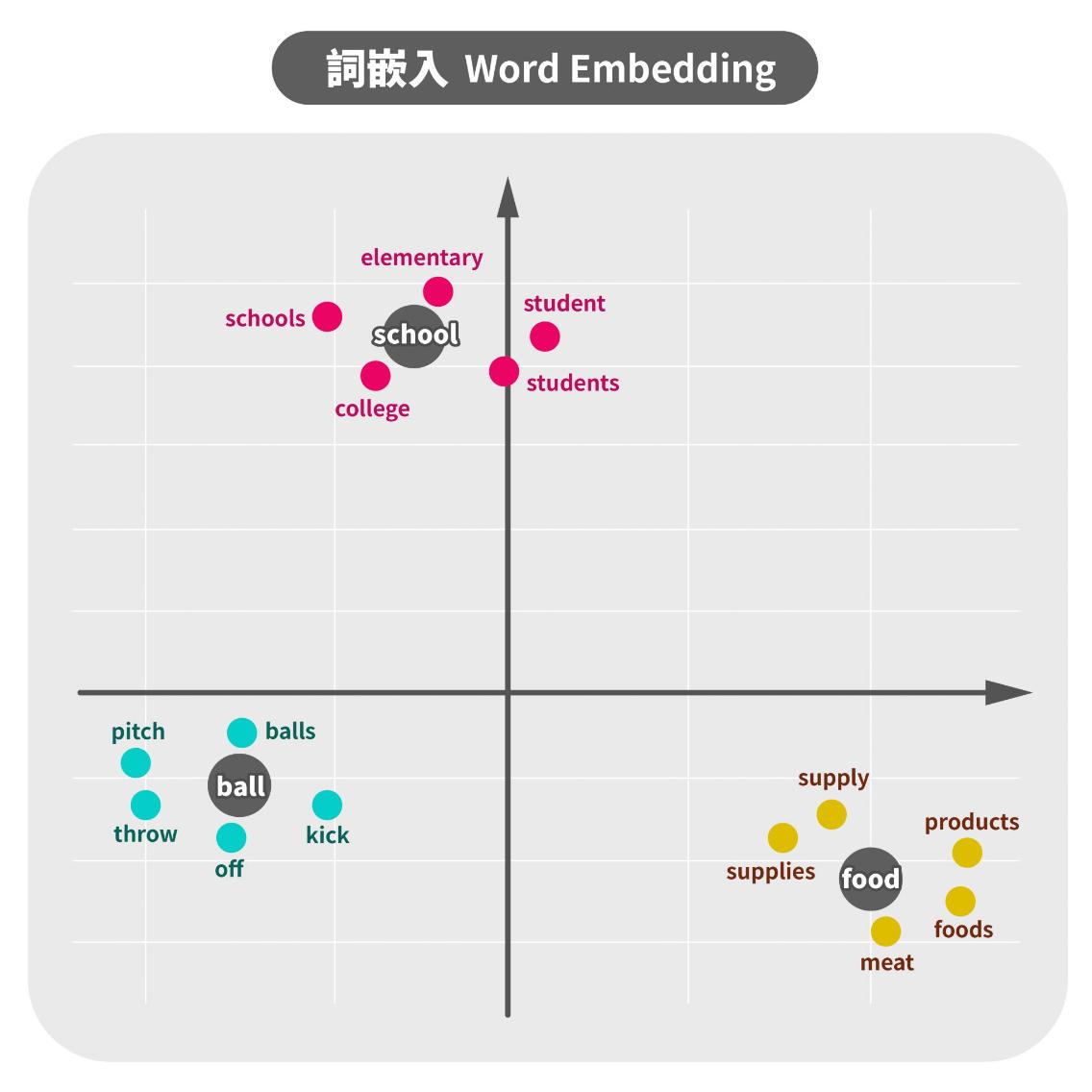
如此一來,透過數值化的向量表達,語言模型在大量文本訓練過程中,可以自動捕捉到每個 Token 之間的關係,常常一起出現的 Token 在向量空間中會比較靠近。
機器不再需要理解語意,只需要記住座標位置,就知道「快樂」和「開心」這兩個很接近的座標,語意是很接近的。進一步做出更好的字詞預測,提高預測準確度。
古倫維提到:「各家拆 Token 的方式都不太一樣,就像早期 Facebook 做詞嵌入訓練的時候,因為社群媒體上很常有口語化的文字,例如『Looooook~』這個字,我們看得懂是 Look,但是對電腦來說就無法理解。所以 Facebook 除了做單詞的嵌入,還會做字母的嵌入,增加準確率。」
當模型愈來愈大的時候,雖然一樣還是要把文字轉換成向量,但古倫維說:「拆分的方法已經不是那麼重要,現在就是在資料裡面找出最常出現的幾個序列去拆分。這些序列可能會看起來很奇怪,不一定有什麼語意,只是統計機率高而已。」
不過,大型語言模型要成功的話,還有「算力」的問題要克服。
平行化與算力:Transformer 架構為何重要?
常聽人說,大型語言模型的基礎是 Google Transformer 架構,古倫維提到:「Transformer 是編碼器加解碼器的完整架構。編碼器是把人看得懂的東西變成電腦才看得懂的東西。當編碼器接收 Token 之後,會進入層層堆疊的神經網路進行深度學習,最後來到解碼器。解碼器再負責把資料轉譯成人看得懂的東西,輸出結果。」
古倫維進一步說,大型語言模型採用 Transformer 架構的優點之一是「平行化」,它可以平行處理資料序列中的所有 Token。當輸入的資料序列很長的時候,Transformer 可以利用「自注意力機制」計算輸入序列的加權總和,並且捕捉到長距離的依賴關係,輸入序列中的每個位置都可以用不同的權重持續關注所有其他位置。這是早期「遞迴神經網路」(RNN)架構無法做到的。
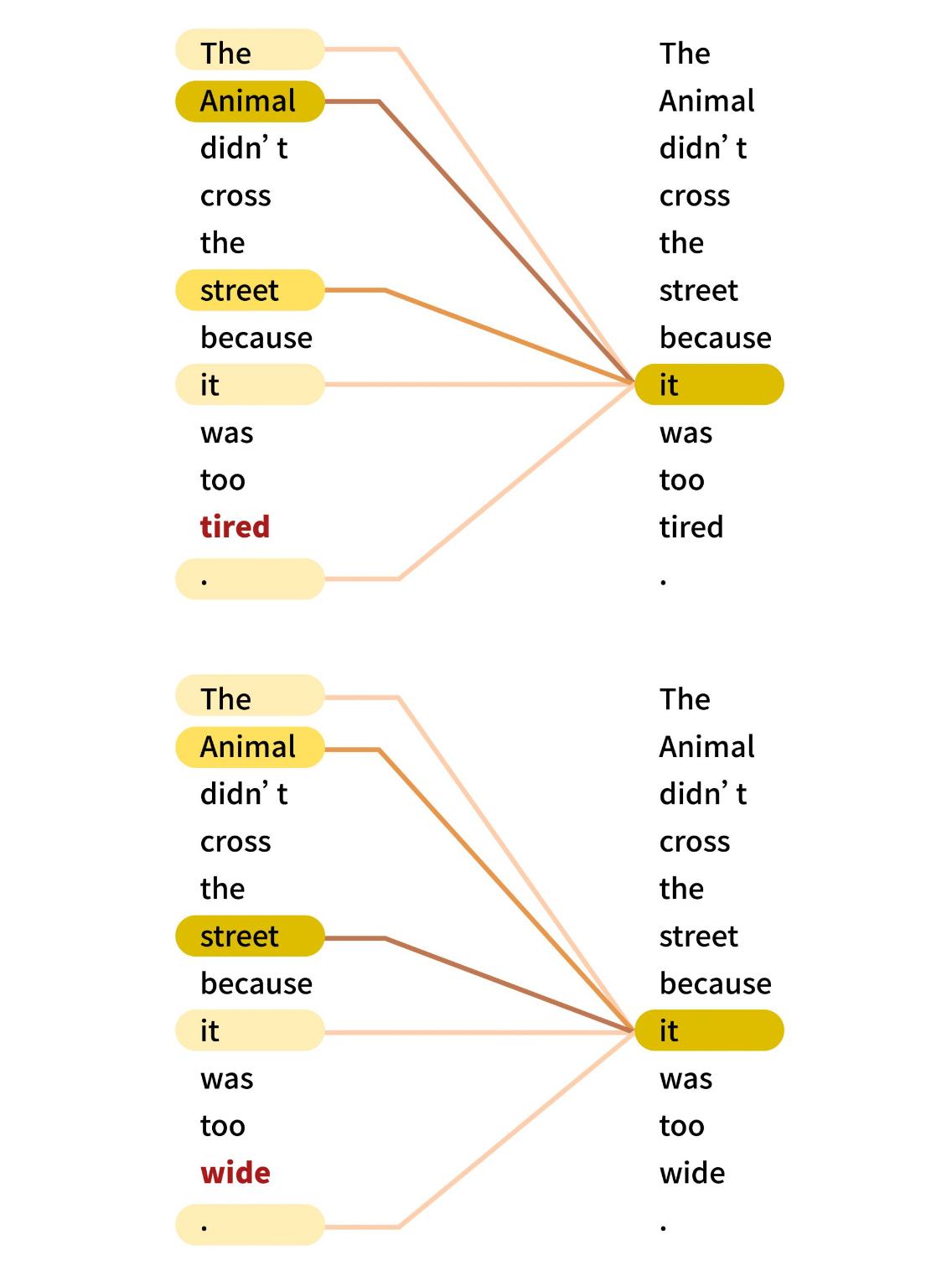
「就像做菜一樣,RNN 一定要把蔥切完,才會開始切菜。」古倫維說,但是對 Transformer 來說,切蔥、切菜和切肉,都可以同步進行。「Transformer 每個步驟都是一次可以看到前面全部的資料,它不會去等過去做完的東西。」她接著說:
平行化就會連結到算力這件事。
在過去,資料需要依序處理,運算單元就是 1 做完再做 2,2 做完再做 3,當資料很長一串時,只能慢慢等。這時候增加再多運算單元也無助於事,因為都塞車在同一顆運算單元。
現在有 Transformer 之後,資料可以做到平行處理,三個步驟就用三顆運算單元同時做完。如果你有 100 顆 GPU,可能 1 秒就能做完 100 個步驟。因此,為什麼新聞上說算力即國力,因為算力會直接影響大型語言模型的開發進度。
古倫維補充:目前常見的大型語言模型,例如 GPT-4 系列,只有用到 Transformer 的解碼器架構,以便更有效率專注在文本與多模態生成任務。
用比喻說明的話,有點像專業考生 GPT-4 已經把全世界歷年考古題的解法背得滾瓜爛熟(預訓練),他不需要知道所有相關的教科書知識,只需要在特定領域加強(微調),就能夠很好的把各種資格考試給考好(完成生成任務)。而且隨著他掌握的解題小秘訣(參數量)愈來愈多,他會考得愈來愈好,不僅可以交叉比對考題形式,甚至可以應用在全新類型的考試上。即便他不是真正了解那些知識,因為語言模型輸出的結果僅代表高機率的統計結果。
另一方面,Transformer 相對於 RNN,也沒有「失憶」的問題。大型語言模型在執行任務時,每次可以處理的文本長度,稱為「上下文窗口」(Context Window),在這個有限窗口以外的 Token,影響力消失的很快。
RNN 架構因為是依序處理,上下文窗口非常有限,當文本長度越長,愈前面的 Token 對輸出結果的影響力愈小。而 Transformer 架構沒有這個問題,它的上下文窗口很大,可以持續捕捉 Token 之間的關係。
我們可以說,Transformer 架構影響了大型語言模型的效能和一次可以處理的資料量。2024 年 5 月時, GPT-4 或 Claude 3,其上下文窗口為 128K-200K 個 Tokens;Google 本家的 Gemini 1.5 Pro,上下文窗口已經達到 2M Tokens!遠遠超越其他廠商。
大型語言模型究竟有多大?愈大愈好嗎?
有了前面的 Token 向量表示法和 Transformer 架構,才能開發出好用的大型語言模型,而大型語言模型的「大」有兩個面向:
首先就是模型參數量(Parameters),再來就是預訓練資料集(Pre-trained Dataset)。延續上個段落,LLM 的模型參數量,就像它擁有的解題小秘訣數量,小秘訣愈多,任務就可以完成的愈好。LLM 的預訓練資料集,就像它事先吸收了多少解題範例,解題範例品質愈好,模型回答的正確性越高。
古倫維說:「通常我們會期待大型語言模型是通用型 LLM,解決各種語言任務。當我們要微調模型時要小心,功能特化很容易讓模型喪失原本的通用能力。」也就是說,如果我們希望做到功能擴充而非功能特化,那就是除了特定領域的知識補充之外,原本模型會的解題小秘訣也不能忘記,要常常複習。
現行 GPT-4 、Claude 3、Copilot、Gemini 1.5 Pro 或 Llama 3 都是通用型 LLM,這些模型即使在預訓練資料有限的情況下,也能有一定的語言理解能力來回應僅有少量線索和規則的問題(Few Shot Learning),或是回應前所未見的問題(Zero Shot Learning)。
可以預見,通用型 LLM 的參數量和預訓練資料量未來會不斷往上增長,因為當模型有大的參數量時,自然就會想要讓電腦吃更多的資料。但至於參數量要到多少才可以稱為「大型」,目前並沒有公認的答案。
從開發者角度來看,大型語言模型的開發者習慣上會以 7 B 參數量作為首要目標,後續依序是 13 B、70 B 等。為什麼大家開發 LLM 都先做 7 B 呢?古倫維坦言:「除了顯卡成本考量之外,也和 Meta 第一個開源 LLM Llama(65B)有關。當時 Llama 的最小瘦身版本就是 7 B。如果開發者要提出一個更好的模型和 Meta 比較,基礎設定當然就是從 7 B 開始。」
一般來說,參數量越大的語言模型,花費成本越高,吃的訓練資料越多,可處理的任務就愈多。
OpenAI GPT-3 的參數量高達 1,750 億(175 B),預訓練資料量有 3,000 億個 Tokens。Meta 開源模型 Llama 3 的參數量最高有 700 億(70 B),預訓練資料量為 15 兆個 Tokens。
然而,無論是 70 B 或 175 B 的參數量,甚至最新的 Llama 3.1 參數量已經來到 4,000 億(405 B),這些模型背後的成本都不是一般研究人員能夠觸及的數字。
大參數模型雖有很高機率可以表現得更好,但是另一方面,表現好的模型卻不一定需要大參數量。
如果只是要針對特定任務和知識領域訓練的話,有機會在有限預算做到最佳化。例如 2024 年主流廠商開始推出 GPT-4o mini 和 Gemini 1.5 flash 等輕量模型,處理每個 Token 的花費成本比原有大模型便宜 50% 以上,並且仍可維持大模型的 80% 以上之性能。
預防假新聞的 LLM 應用
古倫維團隊近年一項研究是「對抗假新聞的傳播」。過去我們都知道第一步是媒體識讀,但是媒體識讀實踐上比較困難的地方在於,每個人的專業和時間有限,故查核能力也很有限,收到訊息通常就是一眼看過、概括接受。
即便媒體事後告知某則新聞為假,但是錯誤訊息已經傳播出去,通常也不會有太多人看到媒體的更正啟事。古倫維表示:「除非新聞資訊和使用者本來的認知有很大衝突時,才會特別去做事實查核。」
因此古倫維提到,他們團隊不做「假新聞偵測」,而是反向思考,利用資訊科學來增加「真新聞的觸及和有效傳播」,而大型語言模型可以更好地完成這個目標。她表示:
既然大型語言模型很會生成文章,那就想辦法讓它根據事實查核的正確資訊來生成吸引人的文章內容和標題,降低記者或事實查核人員的工作負擔。
希望使用者去看真新聞的前提,古倫維說,首先是推播時機,「真新聞的推播時機不適合在使用者看完假新聞之後立刻推播,比較適合在使用者看完假新聞,又持續接觸相關訊息的時候推播,此時真新聞更容易被接受。」
接下來,讓使用者在適合情境接收真新聞之後,就要增加真新聞的吸引程度。古倫維說:「通常網路上的查核新聞都很少人看,我們可以用大型語言模型生成吸引人的內容,吸引使用者點進來。」
然而,使用者真的會受到真新聞的影響,改變認知嗎?古倫維說,這涉及想法上的「Flip」(翻轉),也就是要從相信假新聞,變成否定假新聞、進而相信真新聞。改變想法並沒有想像中容易,使用者對假新聞的感知其實很不敏感。古倫維團隊從研究看到:
90% 的使用者自認對某個新聞事件很熟悉,但是當看到該新聞事件的假新聞時,卻有 50% 以上的人辨識不出來。
「假新聞對我們影響真的很大」,古倫維說,「假新聞就像病毒,當使用者觀看假新聞時,就已經被感染,那我們目的就是要從資訊科學角度設法做『治療』」

2022 年,古倫維團隊已經證實,傳播真新聞的有效形式之一,是針對假新聞的「反事實解釋」,反事實解釋形式的真新聞,會特別強調假新聞與事實互相矛盾的具體證據。古倫維提到,「新聞最重要就是人事時地物,我們就根據這些具體事實去質疑和反駁假新聞。」利用語言模型自動產生 QA 質疑假新聞,最後產生最佳的真新聞(反事實解釋),就是團隊的早期成果。
2023 年,生成式人工智慧技術和大型語言模型飛速進展,基於前述成果,古倫維團隊開始用 GPT-4 來產生真新聞(反事實解釋)。首先,請使用者看完假新聞做前測,回答對新聞事件的認知。然後,一樣請使用者閱讀假新聞,並接著閱讀假新聞下方的警訊:由 GPT-4 產生的真新聞。接著進行後測,觀察使用者是否改變認知。
結果發現,使用者回答問題的準確率(認知到事實的比例),從原本的 41%,提升至 77%,並且過了 24 小時之後,準確率仍有 69%。
這說明團隊用 GPT-4 來生成真新聞的確有效。另外,古倫維在論文中也提到,一般常見的假新聞宣告標語,比如「該訊息為假新聞,已經過第三方事實查核確認」,這類文字形式經過上述同樣的流程驗證後,也有和反事實解釋有類似的改善效果,如果兩者搭配使用,效果可能會更好。未來,研究團隊會考慮真新聞(反事實解釋)在字體呈現、文本長度或內容風格的影響。
2024 年,古倫維團隊最新的研究是:如何把真新聞(反事實解釋)寫得更好?他們已經初步證實,大型語言模型 GPT-4,多次與其他 LLM 或人類交叉提問之後,能夠大幅改善真新聞對使用者的解釋效果,並且已經可以和專家撰寫的解釋相當。未來,如果可以做到平台整合,或許我們就可以利用 LLM 的力量,生成更好更完善的真新聞,來提升整體社會對假新聞的防禦能力。
本文轉載自《研之有物》。原文請<點此>